目次
Whisper(文字起こし)
Whisperとは?
「Whisper」はOpenAIが発表した音声認識モデルです。日本語の音声でも高い精度で文字起こしができるツールとなっています。動画/音声ファイルをアップロードすることで、自動で文字起こしを実行してくれます。スピーチなど話者が一人の場合の精度は非常に高いですが、多人数での会議になると精度が少し下がってしまいます。
文字起こしにかかる時間は、アップロードしたファイルの再生時間×2倍で見ていただければ大丈夫かと思います。
以下の利用手順を参考に、ぜひご使用ください。
利用手順
①以下のリンクへアクセスしてログイン
アカウント情報
メールアドレス:cecfair03@gmail.com
パスワード:CEC12345
以下の画面が出るので赤枠をクリック
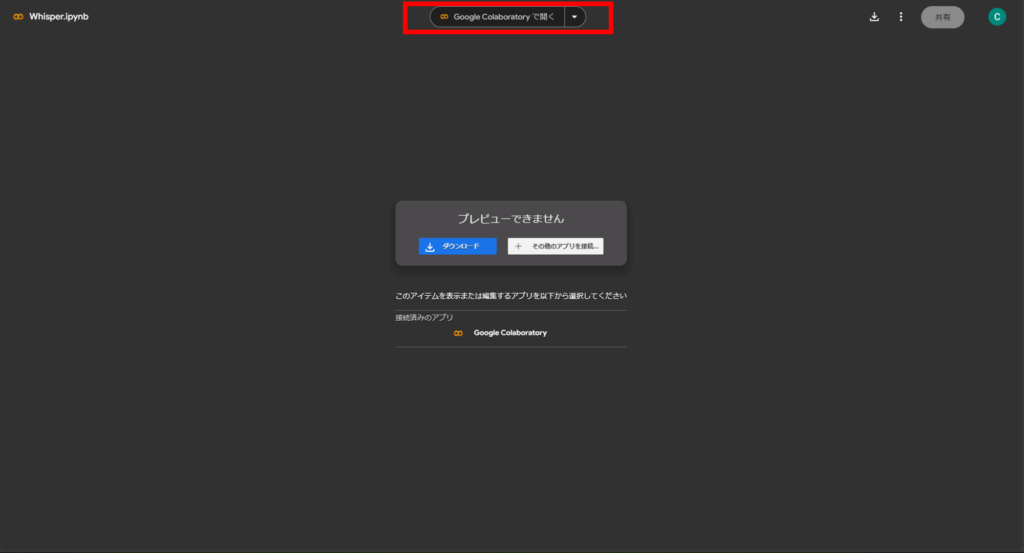
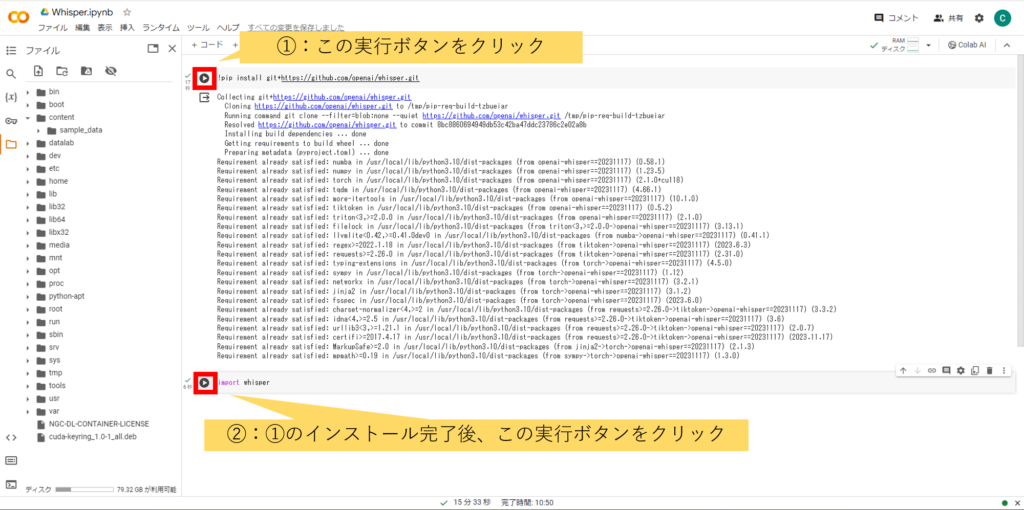
②コードを実行
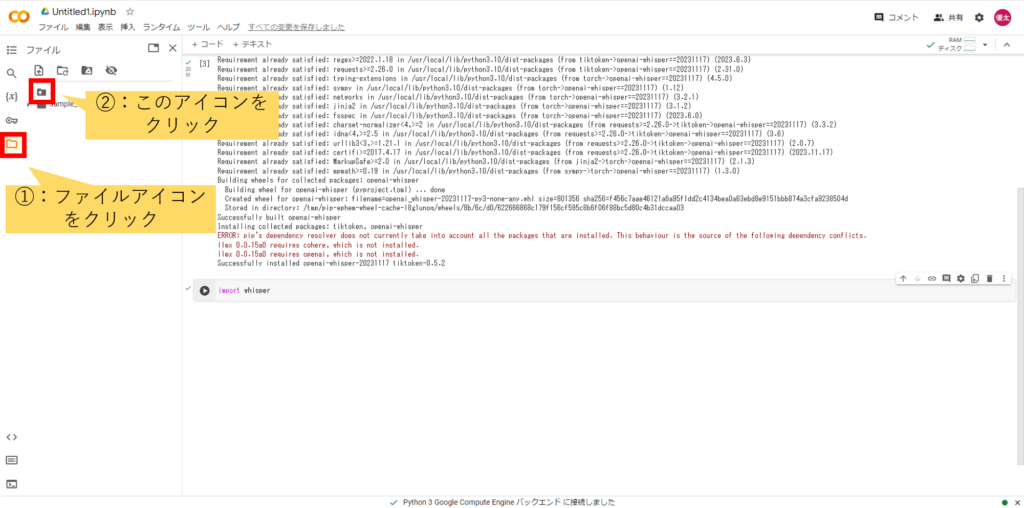
③ファイルアイコンをクリックし、表示される一番上のアイコンをクリック
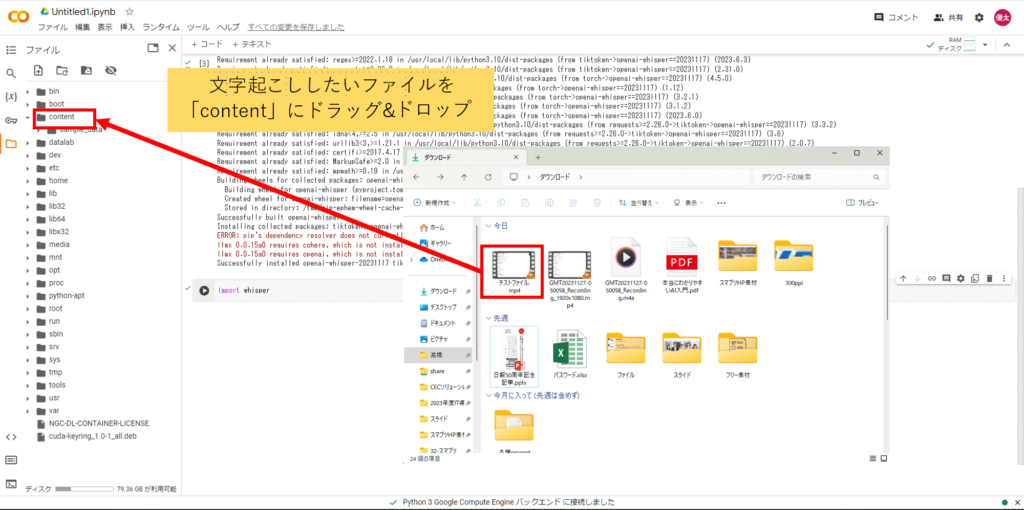
④音声ファイルを「content」内にドラッグ&ドロップ
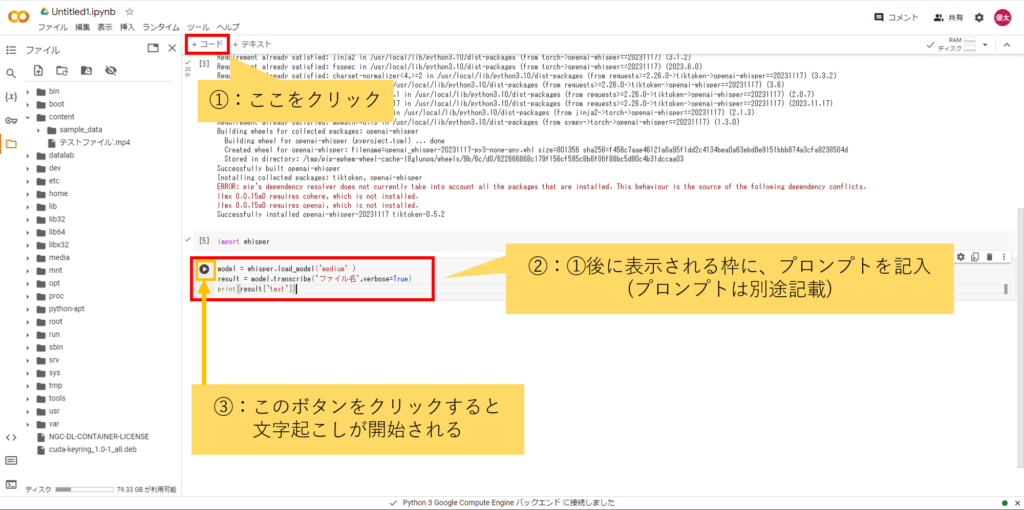
⑤「+コード」クリックで表示される入力欄に、以下のプロンプトを入力。その後、▶ボタンをクリックすると、音声データの文字起こしが始まる
入力プロンプト
model = whisper.load_model(‘medium’)
result = model.transcribe(‘ファイル名‘,verbose=True)
print(result[‘text’])
※ファイル名は文字起こししたいファイルの名前を拡張子含めて記入
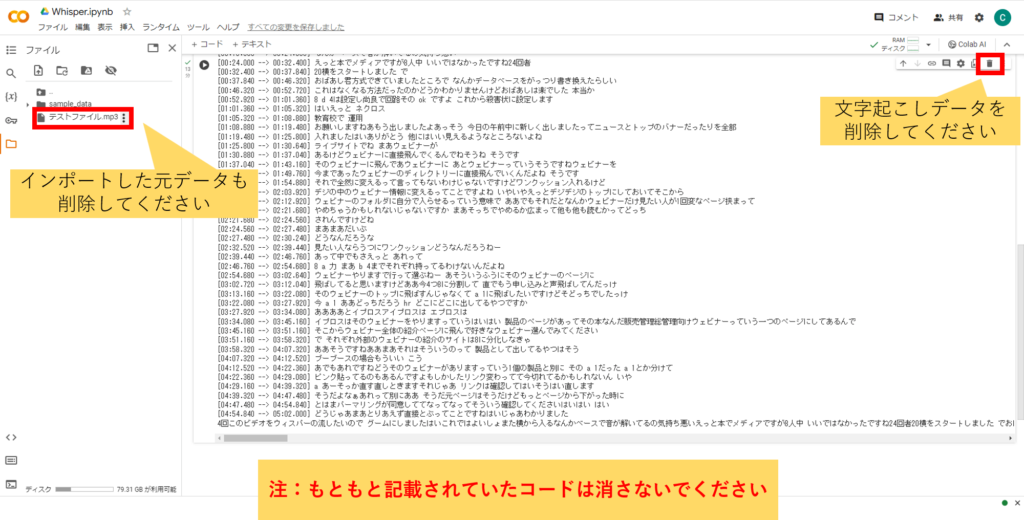
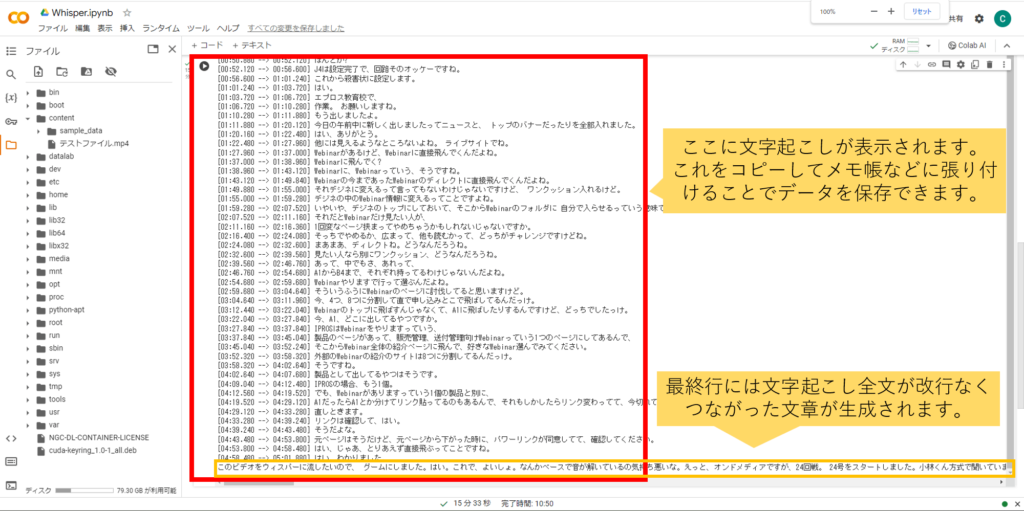
⑥文字起こしが完了したら、必要箇所をコピーして任意のエディタ等に張り付けて保存
⑦文字起こしデータ、インポートした元データを削除してください。この際、もとから記載されていたコードは消さないでください。