

生成AIによる回答を制度を上げるための技術に「RAG(Retrieval-Augmented Generation)」といわれるものがあります。「RAG」はLLM自身が記憶できる以上のコンテキストを外部知識として記憶し、回答生成時にそれを参照することで、精度の高い回答を得るという技術です。例えるなら、試験時にカンニングペーパーを見ながら回答しているイメージです。
しかし、現在主流のLLM、GPT-4oやGemini 1.5 Proでは一度に12万8000トークンもの入力が可能になり、「RAG」を用いずにコンテキストをすべて入力に入れ込んでしまうことが可能になりました。これにより、「RAG」を時代遅れの産物とみなす人もできてきました。
そんな中、「RAGは改良することでまだまだ使える」と信じ研究をしていた人たちは、
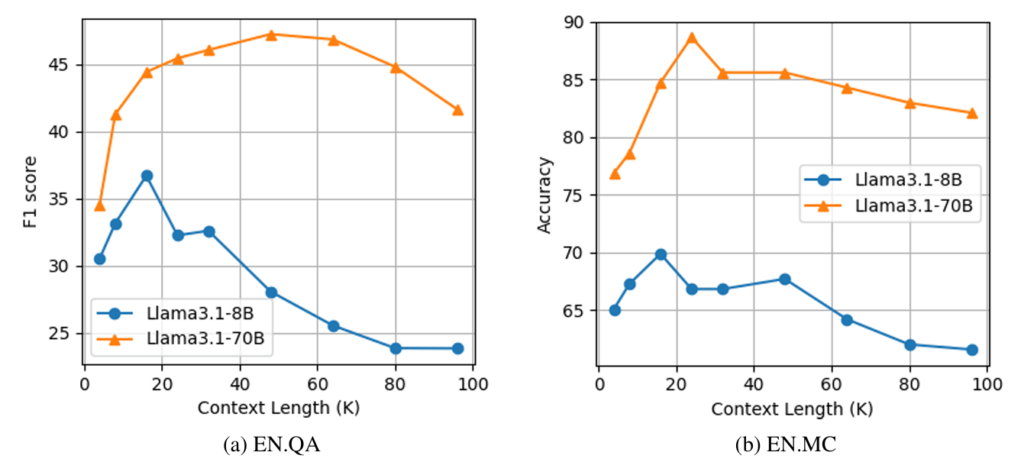
- 長すぎる文脈は、むしろ関連情報への注目を弱めてしまう(図1参照)
- RAGを改良することで、長文脈LLMよりも高性能になる可能性がある
と主張し、「OP-RAG(Order-Preserve RAG)」という新しい手法を発表しました。
この手法では、検索した情報を「関連度順」に並べ替え、「元の文書の順序を保ったまま」情報を使います。
元の順序を保持することで、そのコンテキストに文脈上の意味づけを行い、回答精度を向上させることができます。
実際にただの「RAG」と比較すると、チャンク数が増えるほど精度が高まっていることが分かります。(図2参照)
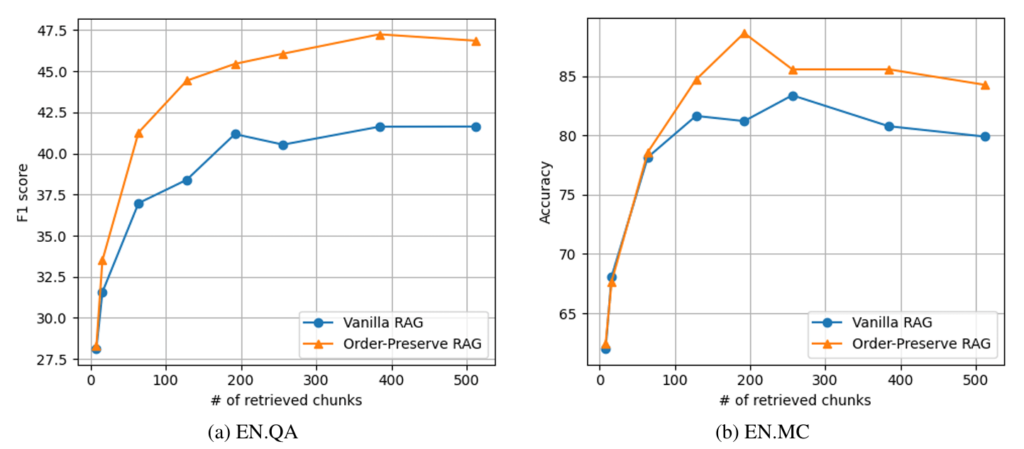
このことから、
- すべてのコンテキストを処理する必要がないため、計算資源の削減が可能
- 少ないトークン数で高精度を実現可能
- 効率的な情報利用で高速な回答が可能
ということが推察できます。
このことは「OP-RAG」をうまく活用することで、「少ないリソースで高性能なAIシステムが作ることができる」ことを表しています。
LLMの進化もさることながら「RAG」を含めた生成AIの周辺技術の進歩もまた目が離せませんね!
参考サイト:https://note.com/ainest/n/nb69c5b585164
元論文:https://arxiv.org/abs/2409.01666